- Date Posted: 7th June 2021
SQL is a query language used to interface with relational databases and stands for Structured Query Language.
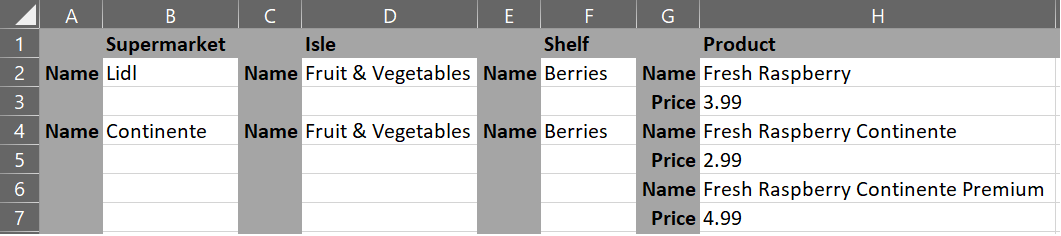
To understand its use, let us pretend we are making a supermarket application to track prices of products across different supermarkets. You could go to these supermarkets and note down the price of the products or use their websites to populate the data on the spreadsheet. Logically, you could track the data as follow:

Or indeed like this:
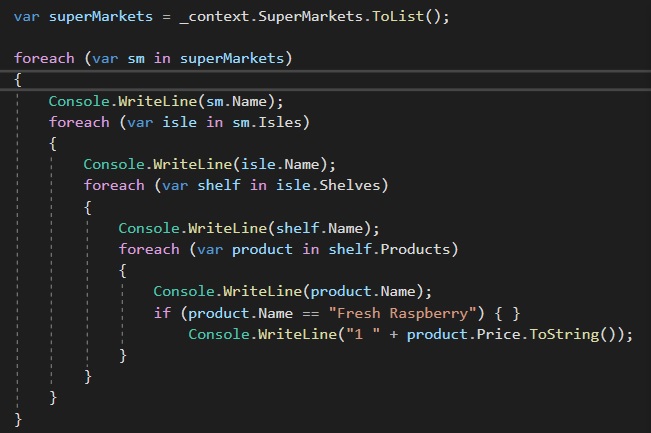
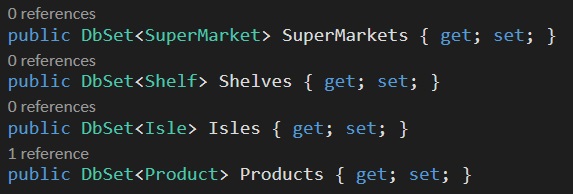
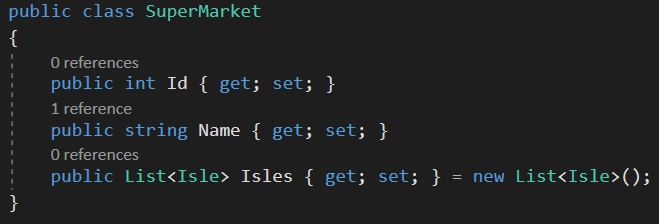
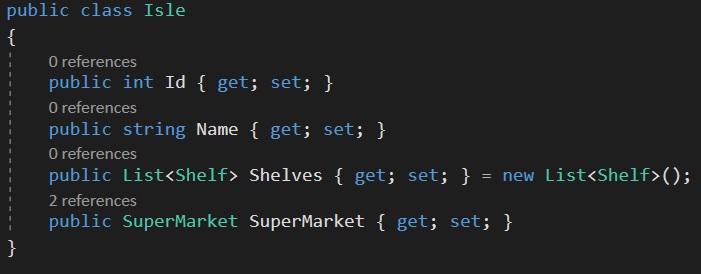
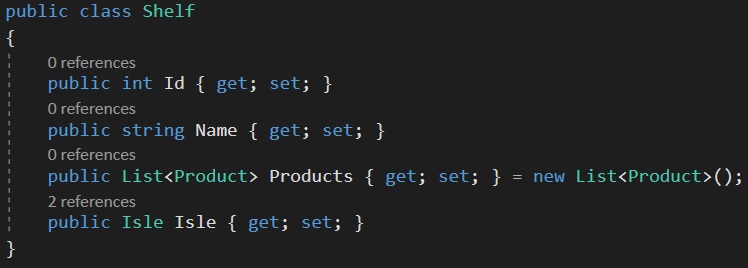
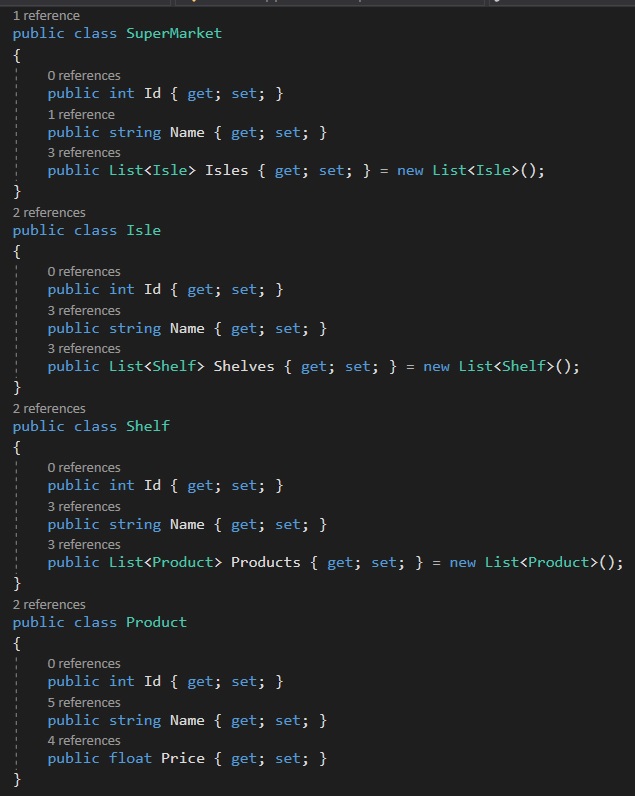
Then you being writing your program that will interact with this data (please ignore the Id property in each class):
Now you are ready to start filling these classes with information from the spreadsheets. You could convert the spreadsheet into a CSV, to be able to parse it as a string in your code. The second spreadsheet example generates this:
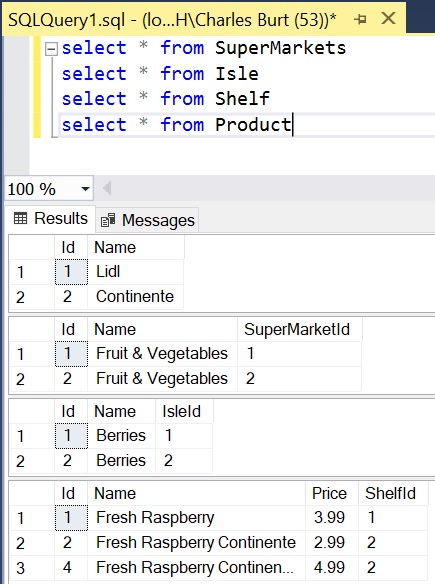
- Supermarket Name,Isle Name,Shelf Name,Product Name,Product Price
- Lidl,Fruit & Vegetables,Berries,Fresh Raspberry,3.99
- Continente,Fruit & Vegetables,Berries,Fresh Raspberry Continente,2.99
- Continente,Fruit & Vegetables,Berries,Fresh Raspberry Continente Premium,4.99
Each line represents a row inside the spreadsheet. This is a workable solution, however Edgar F. Codd invented the relational model for database management, which through complex math, ensures, “…data integrity, …logical and physical data independence from database applications, …guaranteed data consistency and accuracy, …easy data retrieval [and more]” (source).

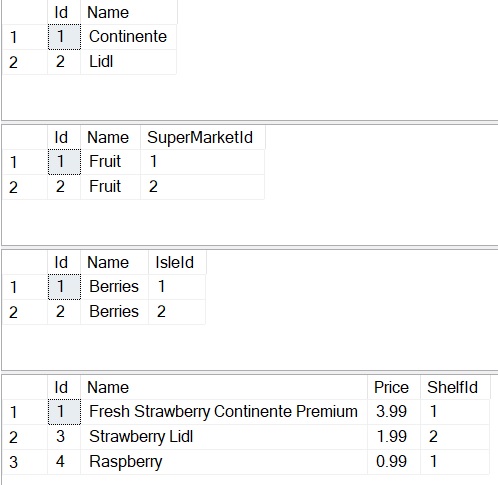
Lets take a look at how our excel data & code would look like inside a relational database set of 4 tables, instead of using a spreadsheet:
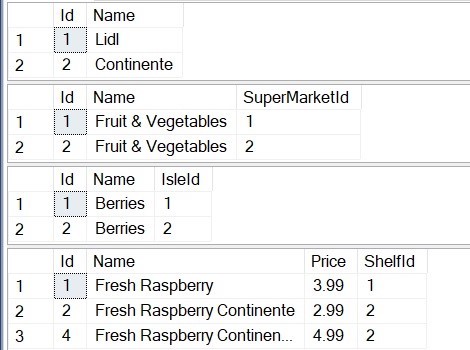
Looks neater and more scalable don’t you think?
Each table could very well be new tabs & sheets in excel; Supermarkets, Isles, Shelves & Products. We would know which products belong to which supermarket by the SuperMarketId, IsleId & ShelfId columns and this would be navigable by code by using those fields, hence this property is referred to as the navigation property.
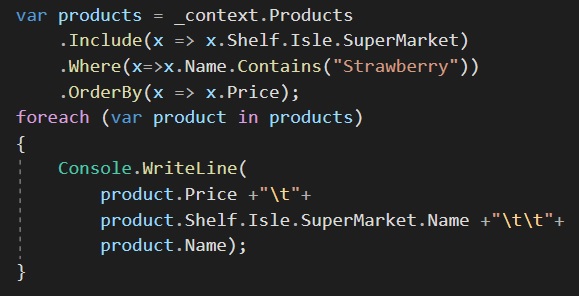
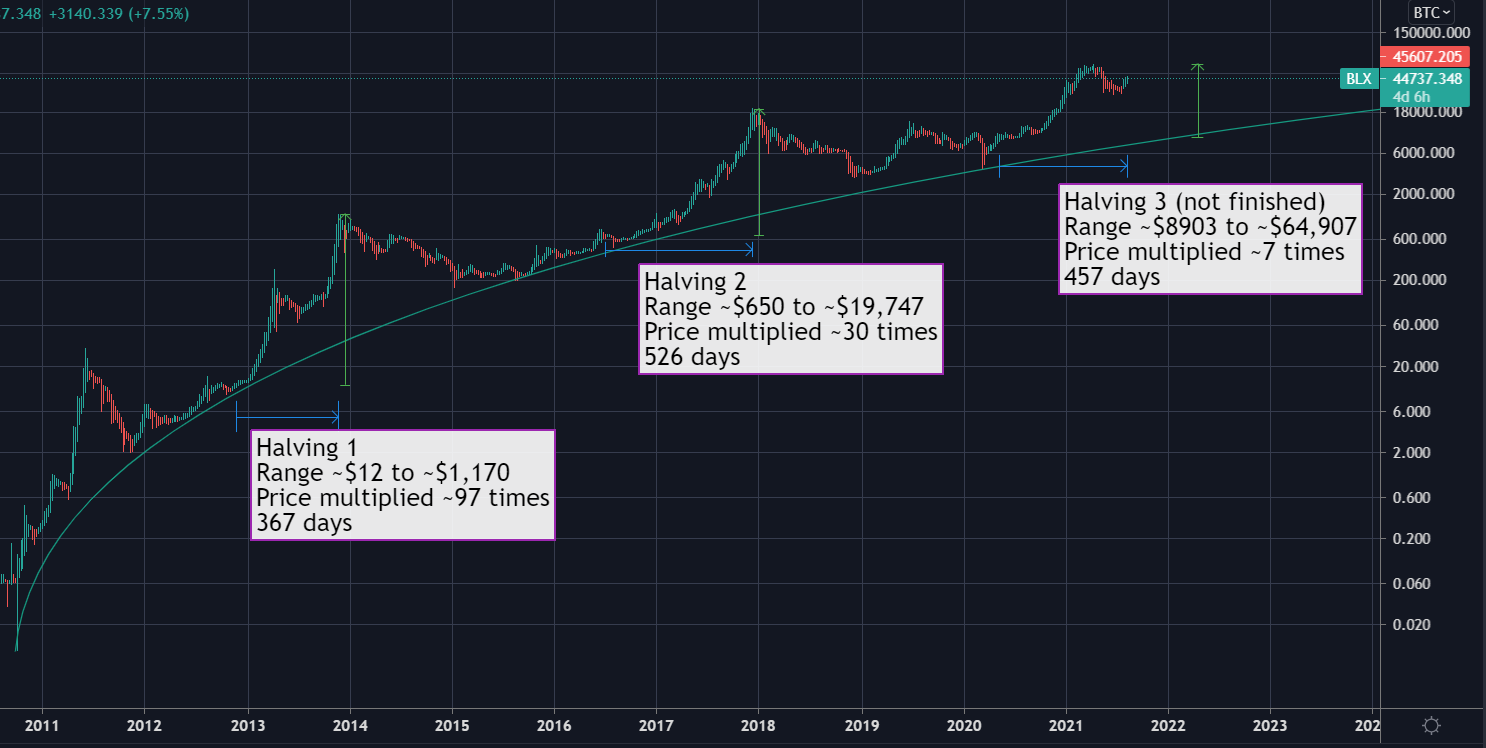
In a program called Microsoft SQL Server Management Studio or SSMS, we can generate a database diagram from the code, here is what it looks like for this example:
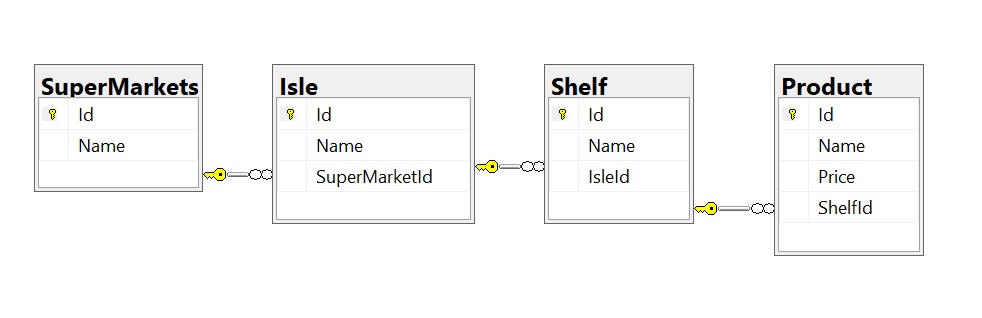
This helps us to visually understand some of what is going on behind the scenes.
Each Id is the “primary key” used to identify the row in the table and each link is represented by the keychain and is called the relationship and contains the “foreign key”.
Each row in the table will have a foreign key pointing to the row in the table it belongs to (its related data), by using a combination of the primary key of that row (or its Id value) and the primary key (the Id value) of the row in question itself. The order of the pairing depends in the direction of the relationship.
A good way of interpreting the keychain symbol is imagining that the key is pointing towards the table that it belongs to, like the Isle belongs to the supermarket, as the supermarket has isles, as defined in our spreadsheet and our code.
- Top